
🌐Why Are Web Robots Used?
How Does This robots.txt File Work and Websites to communicate with web crawlers or spiders

Hi, I’m Wajid Khan. I am trying to explain computer stuff in a simple and engaging manner, so that even non-techies can easily understand, and delivered to your inbox weekly. Join me on an under-the-hood tech journey.
Why Are Web Robots Used?
The robots.txt file is a text file used by websites to communicate with web robots, also known as web crawlers or spiders.
Web robots are used for categorizing web sites. You might think that all robots are friendly because they're indexing web sites with good intentions.
🚨No! That is a misconception. There are good robots and evil robots. Not all robots cooperate with the set standards.
There are e-mail harvesters, spam bots, malware, and other robots that scan for security vulnerabilities in a web portal. These robots usually try to access restricted zones specifically. Instead of staying out, they keep hanging around, hoping to gain access or benefiting in some.
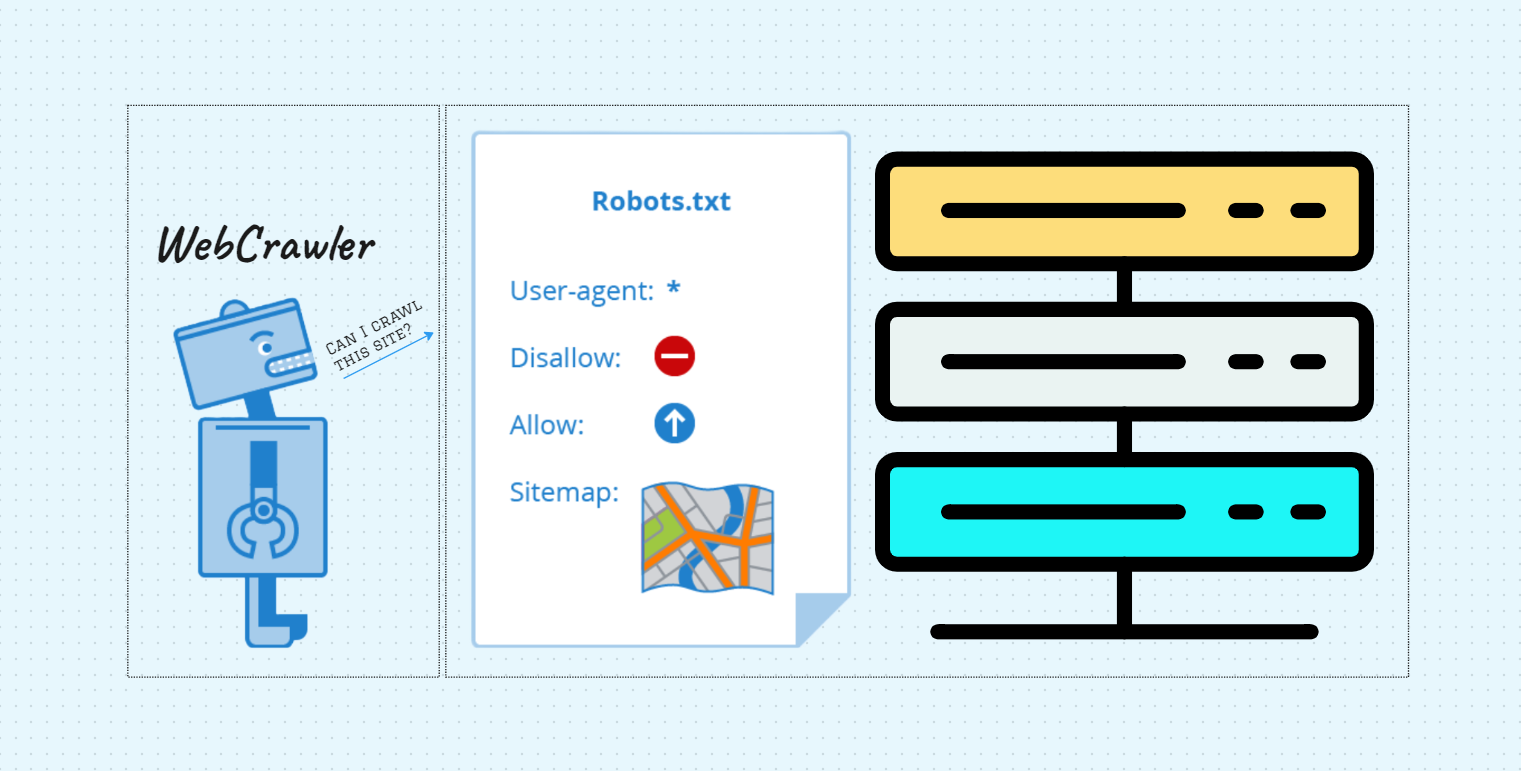
How Does This robots.txt File Work?
Suppose you're a site owner and you want web robots not to crawl the private directory. To do that, you need to place a text file named robots.txt with instructions in the root directory. It looks something like this: www.example.com/robots.txt.
When a web robot comes to your site, it usually searches for the robots.txt file. Then it reads the instructions. If it's a good robot, then it'll never crawl the directory that are private.
If the robots.txt file doesn't exist, the web robots travel the entire site indexing each page, categorizing them accordingly. For the sub-domains, you need to maintain separate robots.txt files in this format: khan.example.com/robots.txt.
Uncovering any Secret Directories
Checking all the information about a web portal is one of the major activities that hackers usually do. The term 'reconnaissance' is used to describe collecting information from all available sources.
This activity is not merely restricted to port scanning, e-mail tracking, or collecting a target's addresses; there is much more to it. Your target might have some private directories that they want to keep outside of search engine searches.
To hide these directories, webmasters usually keep one robots.txt file inside the web root. This is called the robots' exclusion standard. It is also known as the robots exclusion protocol or simply robots.txt.
Normally, search engines crawl web sites to index and place them in their respective search listings. Keeping a robots.txt file in the web root is a standard used by all websites to communicate with web crawlers and other web robots.
🚨This standard enables websites to inform web robots which areas are off-limits.
The robots were instructed to not crawl certain areas of the website. I don't want to be crawled into this section. Listening to this request, the web robot doesn't crawl that part of the site.
Robot.txt File Structure

Here's a summary of the robots.txt file: Purpose: The robots.txt file informs web robots about the website's crawling preferences and any specific instructions regarding access to certain pages or directories. User-agent: This directive specifies the specific web robot or crawler to which the following rules apply. For example, "User-agent: Googlebot" tar…
Final Thought
It's important to note that while the robots.txt file serves as a guide for search engine crawlers, not all robots adhere to its instructions. Some malicious bots or poorly programmed crawlers may ignore or misinterpret the directives. Therefore, it's crucial to implement additional security measures to protect sensitive data or restrict access if necessary.
